
Wiemy, że statystyki systemowe są ważnym opisem wydajności wykorzystywanej platformy sprzętowej oraz że kosztowy optymalizator zapytań Oracle Database odwołuje się do ich wartości podczas szacowania kosztów planów wykonania zapytań (pisaliśmy o statystykach systemowych TU). Wielu administratorów zastanawia się jednak, jak bardzo optymalizator zapytań jest „wrażliwy” na wartości tych statystyk (zbieranych metodami eksperymentalnymi). Aby odpowiedzieć na to pytanie przeprowadźmy prosty eksperyment.
Dana jest tabela o rozmiarze 375 bloków, zawierająca 100 tysięcy rekordów o średniej długości 22 bajtów. Na jednej z kolumn tej tabeli utworzony został indeks (współczynnik clustering_factor=371). Użytkownicy wykonują zapytania wykorzystujące predykat oparty na indeksowanej kolumnie. Zapytania te mają różne selektywności. Postanawiamy sprawdzić, dla jakiej granicznej selektywności stosowany będzie ten indeks (powyżej niej nastąpi pełen odczyt). Testy wykonujemy dla różnych proporcji statystyk systemowych SREADTIM (czas wykonywania odczytu dyskowego swobodnego) i MREADTIM (czas wykonywania odczytu dyskowego wieloblokowego) – przykładowo, gdy SREADTIM=5ms a MREADTIM=10ms, to proporcja wynosi 0.5. Wyniki eksperymentu na platformie Oracle Database 12.2 obrazuje poniższy wykres.
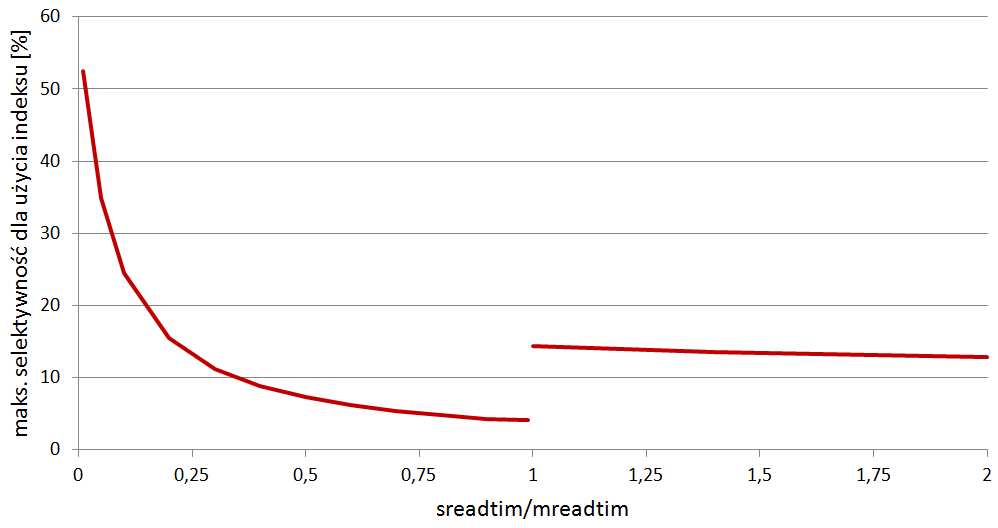
Komentarz jest następujący. Relacja pomiędzy statystykami systemowymi SREADTIM i MREADTIM ma decydujący głos w procedurze decydowania czy zostanie użyty indeks, czy też wykonany zostanie pełen odczyt tabeli. Gdy SREADTIM był sto razy mniejszy od MREADTIM, kosztowy optymalizator zapytań proponował użycie indeksu nawet dla zapytań o selektywości przekraczającej 50%! Z kolei gdy SREADTIM miało wartość bliską MREADTIM, indeks przestawał być używany już przy selektywności 4-5%.
Zastanawiające jest też widoczne na wykresie „zerwanie” przebiegu krzywej, gdy zrównują się wartości SREADTIM i MREADTIM. Zjawisko to wynika z innego zachowania się optymalizatora zapytań w przypadku, gdy MREADTIM<SREADTIM – w takiej sytuacji (czasami występującej na macierzach dyskowych stosujących agresywny read-ahead) optymalizator przestaje uwzględniać wartość statystyki systemowej MREADTIM. Pisano o tym wiele lat temu na blogu AskTom.
Jeżeli więc ktoś się zastawia, dlaczego identyczne zapytania wykonywane na identycznych bazach danych, ale osadzonych na różnych maszynach, stosują inne plany wykonania, to jednym z winowajców mogą być właśnie statystyki systemowe.
Dla przypomnienia – jak ustawiać i odczytywać statystyki systemowe:
- select pname, pval1 from sys.aux_stats$ where sname = 'SYSSTATS_MAIN’;
- dbms_stats.set_system_stats(’sreadtim’, <value>);
- dbms_stats.set_system_stats(’mreadtim’, <value>);
Panie Macieju w aux_stats jest też CPUSPEED – jak to rozumieć? Pzdr!
Witam serdecznie! CPUSPEED reprezentuje średnią szybkość procesora mierzoną w milionach cykli na sekundę. Np. statystyki zebrane w tej chwili na moim laptopie z procesorem taktowanym 2.8 GHz pokazują CPUSPEED=2673. Dość ważna dla optymalizatora zapytań jest proporcja szybkości procesora do szybkości dysku, bo odbija się potem na decyzjach o wyborze plany wykonania.