
W tabelach typu Heap (najpopularniejsze, domyślne) kolejność fizycznego ułożenia rekordów jest zasadniczo przypadkowa, wynikająca m.in. z porządku ich wstawiania. Kolejność ta nie ma żadnego znaczenia dla wydajności zapytań dokonujących pełnego odczytu tabeli lub jednorekordowych zapytań punktowych z użyciem indeksu. Ma jednak znaczenie dla wydajności realizacji zapytań zakresowych z użyciem indeksu, gdzie wynikowy zbiór rekordów tabeli jest odczytywany na podstawie referencji ROWID znajdujących się w liściu (sąsiednich liściach) indeksu. Od tego, czy referencje te są „sąsiednie” czy „rozproszone” w dużej mierze zależy koszt wykonania zapytania.
Przyjrzyjmy się jak zmienia się wydajność zapytania zakresowego z użyciem indeksu w zależności od tego, czy rekordy tabeli są fizycznie posortowane względem kolumny selekcji, czy też nie. Zbudujemy dwie identyczne pod względem zawartości tabele – PRODS_BY_ID, w której rekordy ułożone są według rosnących wartości kolumny PROD_ID i PRODS_BY_PRICE, w której rekordy ułożone są według rosnących wartości kolumny PROD_PRICE. Tabele będą liczyć 100 milionów rekordów każda.
create table prods_by_id(
prod_id number(10),
prod_name varchar2(2000),
prod_price number(8,2));
begin
for i in 1..100000000 loop
insert into prods_by_id values (i, 'DUMMY', dbms_random.value(1,1000));
end loop;
end;
/
create table prods_by_price
as select * from prods_by_id order by prod_price;
Następnie dla każdej z tabel utworzymy indeks na kolumnie PROD_PRICE.
create index pbid_idx on prods_by_id(prod_price);
create index pbprice_idx on prods_by_price(prod_price);
Zauważmy istotną różnicę pomiędzy tymi indeksami. W przypadku indeksu PBID_IDX sąsiednie wpisy w liściu indeksu z dużym prawdopodobieństwem wskazują różne bloki tabeli, natomiast w przypadku indeksu PBPRICE_IDX spodziewamy się, że sąsiednie wpisy w liściu indeksu zwykle trafiają w ten sam blok tabeli. Różnicę tę obrazuje poniższy rysunek – po lewej stronie sytuacja z indeksu PBID_IDX, po prawej – z indeksu PBPRICE_IDX. Ponieważ zapytanie zakresowe odczytuje ciągły zakres liścia lub liści indeksu, to istotne jest, czy temu zakresowi odpowiada mała czy duża liczba wskazywanych bloków tabeli.
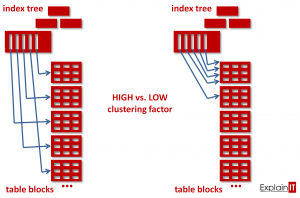
O tym, jak „zgodnie” rekordy tabeli są fizycznie ułożone w stosunku do kolejności wpisów w liściach indeksu możemy się dowiedzieć odczytując statystykę CLUSTERING_FACTOR dla indeksu. Jeżeli jej wartość jest bliska liczbie bloków tabeli, to oznacza to, że rekordy tabeli są posortowane zgodnie z indeksem. Jeżeli natomiast jej wartość zbliża się do liczby rekordów tabeli, oznacza to zupełnie chaotyczną organizację fizyczną. Poniżej przedstawiamy odczyty dokonane podczas eksperymentu.
select index_name, clustering_factor
from dba_indexes
where index_name like 'PB%';
INDEX_NAME CLUSTERING_FACTOR
----------- -----------------
PBPRICE_IDX 510294
PBID_IDX 98987023
select table_name, blocks from
dba_tables
where table_name like 'PRODS_BY%';
TABLE_NAME BLOCKS
-------------- ------
PRODS_BY_ID 308585
PRODS_BY_PRICE 303461
Jak teraz różnice wskaźników Clustering Factor odbiją się na wydajności zapytań zakresowych z użyciem indeksu? Sprawdźmy to, wykonując jednakowe zapytanie zakresowe do tabeli chaotycznie zorganizowanej fizycznie (PRODS_BY_ID), a następnie do tabeli, której rekordy są ułożone w kolejności zgodnej z indeksem (PRODS_BY_PRICE).
select max(prod_name) from prods_by_id where prod_price between 50 and 60;
...
Elapsed: 00:01:20.44
Execution Plan
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows|Bytes|Cost |
-----------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 1| 11|1003K (1)|
| 1 | SORT AGGREGATE | | 1| 11| |
| 2 | TABLE ACCESS BY INDEX ROWID BATCHED|PRODS_BY_ID|1002K|10M|1003K (1)|
|* 3 | INDEX RANGE SCAN | PBID_IDX |1002K| | 2229 (1)|
-----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1001614 consistent gets
select max(prod_name) from prods_by_price where prod_price between 50 and 60;
...
Elapsed: 00:00:00.19
Execution Plan
----------------------------------------------------------------------------
| Id | Operation | Name | Rows|Bytes|Cost |
----------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 1 | 11|7497 (1)|
| 1 |SORT AGGREGATE | | 1 | 11| |
| 2 | TABLE ACCESS BY INDEX ROWID BATCHED|PRODS_BY_PR|1002K| 10M|7497 (1)|
|* 3 | INDEX RANGE SCAN |PBPRICE_IDX|1002K| |2232 (1)|
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
5003 consistent gets
Wyniki pokazały przepaść wydajnościową – 80 sekund do 200 milisekund – wynikającą oczywiście z innej organizacji fizycznej rekordów tabeli. Tabela, której rekordy zostały posortowane zgodnie z kolumną indeksu służącego do optymalizacji zapytań zakresowych (PRODS_BY_PRICE), umożliwiła wykonanie zapytania w imponująco krótkim czasie (w porównaniu do scenariusza chaotycznego układu fizycznego rekordów).
panie macieju – jedno pytanko – jak moge posortowac krotki w tabeli zeby poprawic clustering fact?
Nie jest to proste, ponieważ Oracle nie oferuje gotowej komendy służącej do fizycznego przesortowania rekordów. Pozostaje po prostu przepisanie rekordów do jakiejś tabeli tymczasowej, wyczyszczenie oryginalnej, a następnie przepisanie z powrotem, ale już w porządku posortowanym.